So, you are working in computational astrophysics and running a lot of simulations is part of your life. A likely challenge you are facing is: how to effectively store your data and process them. This means a couple of things: first, you want to reduce the size of your datasets as much as possible without sacrificing the accuracy or resolution, because you know that you only have limited amounts of storage space and also smaller files can be shared with colleagues more easily. Second, you want to share with your colleagues who may be using a different operating system and data processing program than yours. You want them to be able to read your data correctly. Third, you want to archive your data, so that you can revisit then even after many years.
The solution to these requirements can probably be addressed from two aspects: first, we could use a widely used data format to ensure the interoperability. This data format must be available to as many platforms and programming languages as possible. Second, we must reduce the redundancy of our simulation data as much as possible.
A few options come to mind regarding the first aspect. HDF5, CDF. FITS are widely used formats in science and/or astronomy. HDF5 offers better support in hierarchical data structures and parallel I/O. It also provides facilities for partial I/O, which is very useful for large datasets. FITS are mainly for observational/imagery data. Given that HDF5 offers more features than the other two, it is chosen as the underlying data format for simulation data.
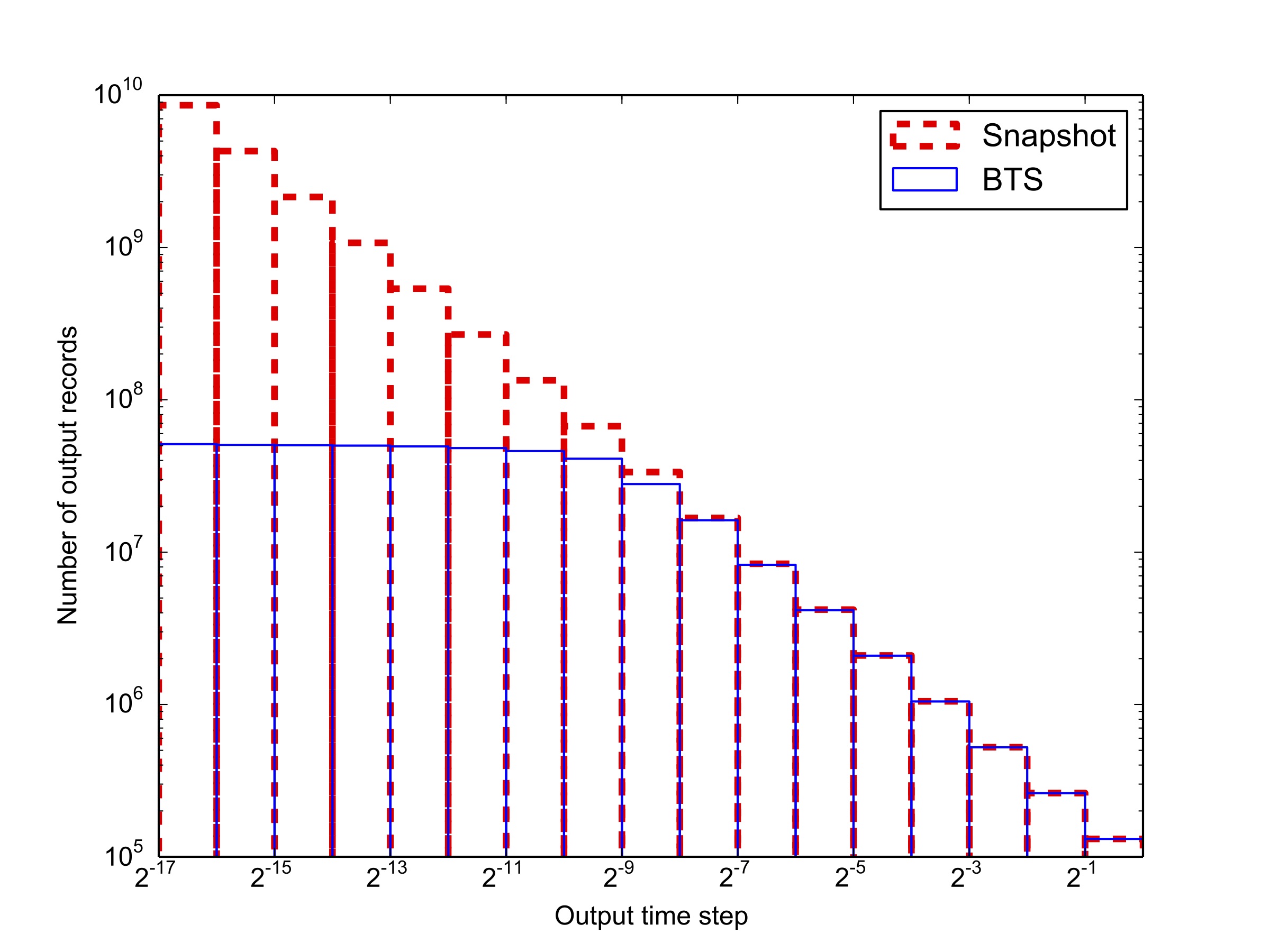
For the second aspect, data redundancy can be largely reduced if we store data incrementally, i.e., only when a particle is updated. By default, we take snapshots of an N-body system periodically and save the data of all particles each time. However, the integrator does not necessarily integrate each particle in each time step. In fact, many N-body codes, especially the codes used in star cluster simulations, employ the so-called "individual time step" integration scheme. For active particles (e.g., in the dense regions of the system, experiencing strong gravitational interactions with other particles), they are integrated more frequently. Inactive particles may be moving largely unperturbed, so to save the computational resource, they do not need to be integrated every single time step. Naturally, their information remains unchanged until the next integration -- no need to be saved to file in this case.